Abstract
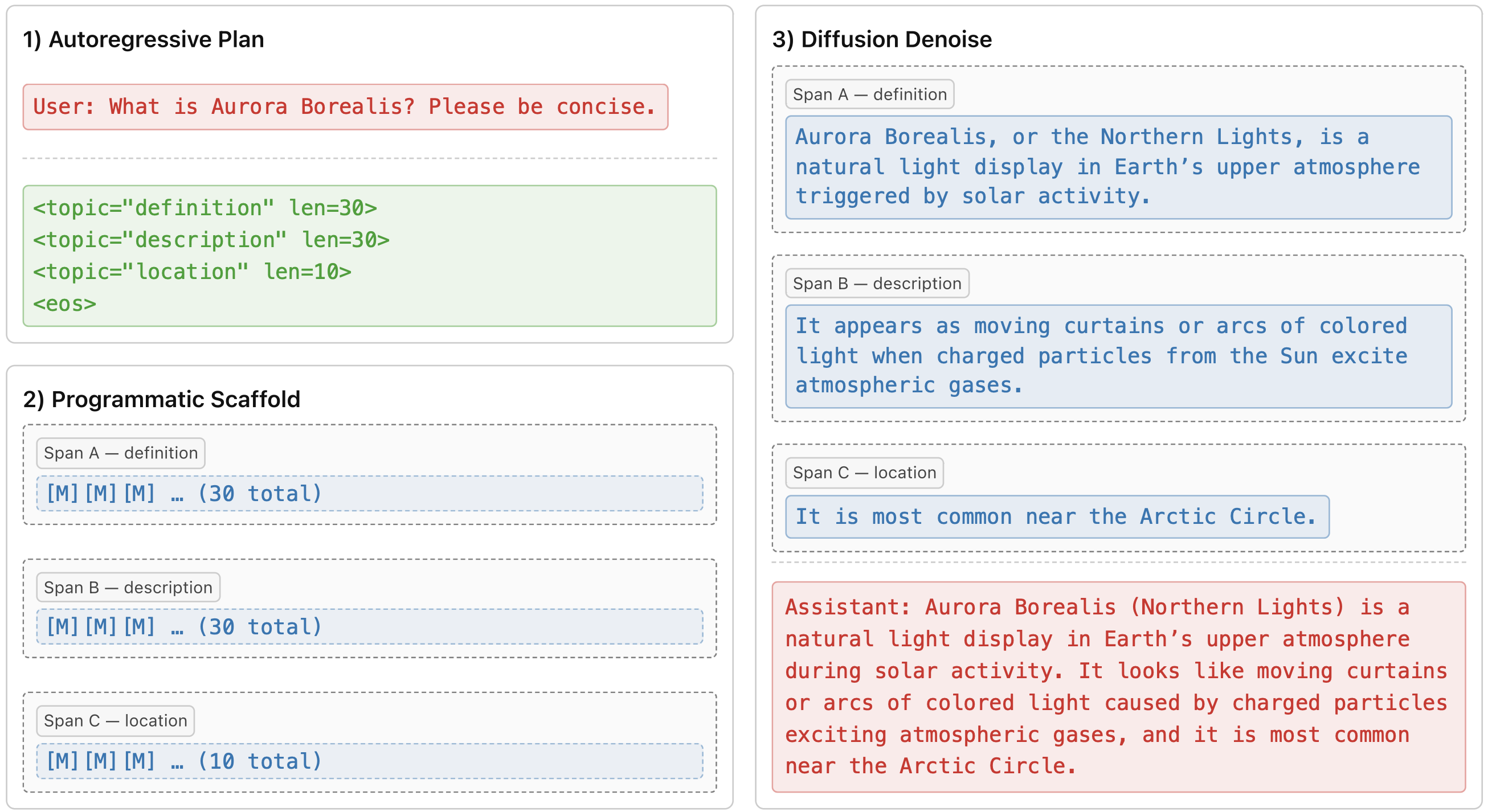
A central challenge in large language model inference is the trade-off between generation speed and output quality. Autoregressive models produce high-quality text but generate tokens sequentially. Diffusion models can generate tokens in parallel but often need many iterations to match the same quality. We propose planned diffusion, a hybrid method that combines the strengths of both paradigms. Planned diffusion works in two stages: first, the model creates a short autoregressive outline that breaks the output into smaller, independent spans. Second, the model generates these spans simultaneously using diffusion. This approach expands the speed–quality Pareto frontier and provides a practical path to faster, high-quality text generation. On AlpacaEval, a suite of 805 instruction-following prompts, planned diffusion achieves Pareto-optimal trade-off between quality and latency, achieving 1.84x speedup over autoregressive generation with only a 6.8% drop in win rate. Our sensitivity analysis confirms that the internal planning of our model is reliable and offers tunable control over the trade-off between generation speed and quality.